
免费下载
夸克:https://pan.quark.cn/s/1923534a2d86
迅雷:https://pan.xunlei.com/s/VNxcqxNWyfF6Z7TzMuEsiUlXA1?pwd=u9v5#
来源github作者:layerdiffusion
layerdiffuse插件可以生成透明图层的图像,文生图和图生图均可使用,同样也兼容SD1.5/SDXL模型,
传送门
[ri-alerts color=”primary”]SD-WebUI-ForgeUI本地部署[/ri-alerts]
模型
该插件目前有13个算法模型,我们在使用的时候会自动下载(注:良好的网络环境)解释如下:
- layer_xl_transparent_attn.safetensors这是一个 256 级 LoRA,可将 SDXL 变成透明图像生成器。它将模型的潜在分布更改为可以通过特殊 VAE 管道解码的“透明潜在空间
- layer_xl_transparent_conv.safetensors这是将 SDXL 变成透明图像生成器的替代模型。该安全张量文件包含所有转换层的偏移量(实际上,所有不是任何关注层的 q、k、v 的层)。这些偏移可以合并到任何 XL 模型中,以将潜在分布更改为透明图像。因为我们排除了任何 q,k,v 层的偏移训练,所以对 SDXL 的即时理解应该被完美保留。然而,在实践中,我发现这layer_xl_transparent_attn.safetensors会带来更好的结果。layer_xl_transparent_conv.safetensors对于一些需要特别提示理解的特殊用例,这仍然包括在内。此外,该模型可能会对基础模型产生强烈的风格影响。
- layer_xl_fg2ble.safetensors这是一个安全张量文件,包含将 SDXL 转换为图层生成模型的偏移量,该模型以前景为条件,并生成混合合成。
- layer_xl_fgble2bg.safetensors这是一个安全张量文件,包含将 SDXL 转换为图层生成模型的偏移量,该模型以前景和混合合成为条件,并生成背景。
- layer_xl_bg2ble.safetensors这是一个安全张量文件,包含将 SDXL 转换为图层生成模型的偏移量,该模型以背景为条件,并生成混合合成。
- layer_xl_bgble2fg.safetensors这是一个安全张量文件,包含将 SDXL 转换为图层生成模型的偏移量,该模型以背景和混合合成为条件,并生成前景。
- vae_transparent_encoder.safetensors这是一个图像编码器,用于从像素空间中提取潜在偏移。可以将偏移添加到潜像中以帮助透明度的扩散。请注意,在本文中,我们使用了一个相对较重的模型,其参数数量与 SD VAE 完全相同。发布的模型重量更轻,需要更少的 vram,并且不会影响我的测试结果质量。
- vae_transparent_decoder.safetensors这是一个图像解码器,以 SD VAE 输出和潜在图像作为输入,并输出真实的 PNG 图像。该模型架构也比纸质版本更轻量,以减少 VRAM 需求。我已确保减少的参数不会影响结果质量。
- layer_sd15_vae_transparent_encoder.safetensors与上述 VAE 编码器相同,但针对 SD1.5 进行了微调。
- layer_sd15_vae_transparent_decoder.safetensors与上面的 VAE 解码器相同,但针对 SD1.5 进行了微调。
- layer_sd15_transparent_attn.safetensors这是一个 256 级 LoRA,可将 SD1.5 变成透明图像生成器。它将模型的潜在分布更改为可以通过特殊 VAE 管道解码的“透明潜在空间”。
- layer_sd15_joint.safetensors该模型文件允许与 SD1.5 一起生成所有层。它包括两个 256 级 lora(前景 lora 和背景 lora),以及一个注意力共享模块,用于在多个扩散过程之间共享注意力。请注意,与纸张不同的是,该模型文件包含一个额外的“混合 lora”,它实际上可以一起生成三个图像(fg、bg 和混合图像)。在我们最近的测试中,与 fg 和 bg 一起生成混合图像有助于理解结构。
- layer_sd15_fg2bg.safetensors该模型文件允许使用 SD1.5 从前景生成背景。它包括一个 256 级 lora 和一个注意力共享模块,用于在多个扩散过程之间共享注意力。该模型文件包含一个附加的“混合lora”,它实际上可以一起生成两个图像(背景和混合图像)。在我们最近的测试中,与 bg 一起生成混合图像有助于结构理解。此外,为了节省 VRAM,fg 直接作为控制信号馈入所有注意力层,而不是创建另一个扩散通道。
- layer_sd15_bg2fg.safetensors该模型文件允许使用 SD1.5 从背景生成前景。它包括一个 256 级 lora 和一个注意力共享模块,用于在多个扩散过程之间共享注意力。该模型文件包含一个附加的“混合 lora”,它实际上可以一起生成两个图像(fg 和混合图像)。与 fg 一起生成混合图像有助于我们最近的测试中的结构理解。此外,为了节省 VRAM,bg 直接作为控制信号馈入所有注意力层,而不是创建另一个扩散通道。
模型存放路径
\stable-diffusion-webui-forge\models\layer_model
如果没有这个layer_model文件,直接新建
模型地址:https://huggingface.co/LayerDiffusion/layerdiffusion-v1/tree/main (需要科学上网,如果没有请在页面,登录下载)
透明图像测试结果
SD1.5模型
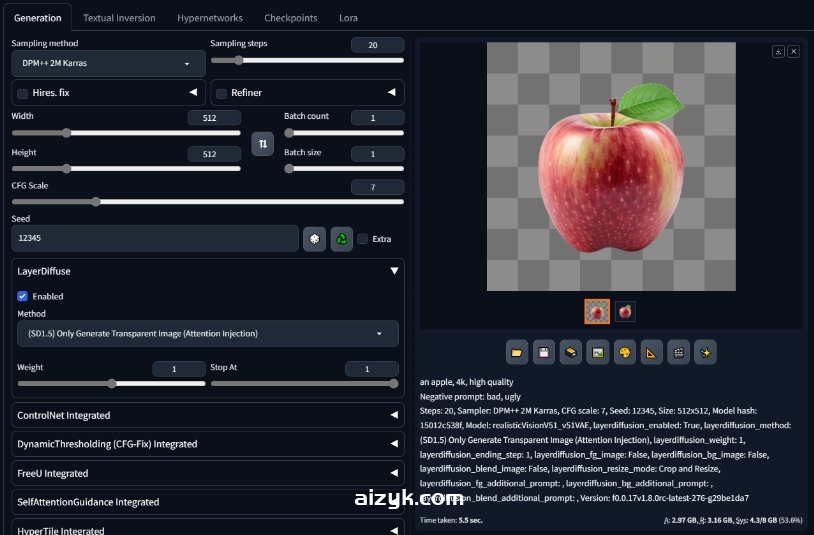
测试的建议模型“realisticVisionV51_v51VAE”(如果你想结果一样的话,模型也在资源包下载好了)
正面提示:an apple, 4k, high quality
负面提示:bad, ugly
其他参数:Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 12345, Size: 512×512, Model hash: 15012c538f, Model: realisticVisionV51_v51VAE, layerdiffusion_enabled: True, layerdiffusion_method: (SD1.5) Only Generate Transparent Image (Attention Injection), layerdiffusion_weight: 1, layerdiffusion_ending_step: 1, layerdiffusion_fg_image: False, layerdiffusion_bg_image: False, layerdiffusion_blend_image: False, layerdiffusion_resize_mode: Crop and Resize, layerdiffusion_fg_additional_prompt: , layerdiffusion_bg_additional_prompt: , layerdiffusion_blend_additional_prompt: , Version: f0.0.17v1.8.0rc-latest-276-g29be1da7
SDXL模型
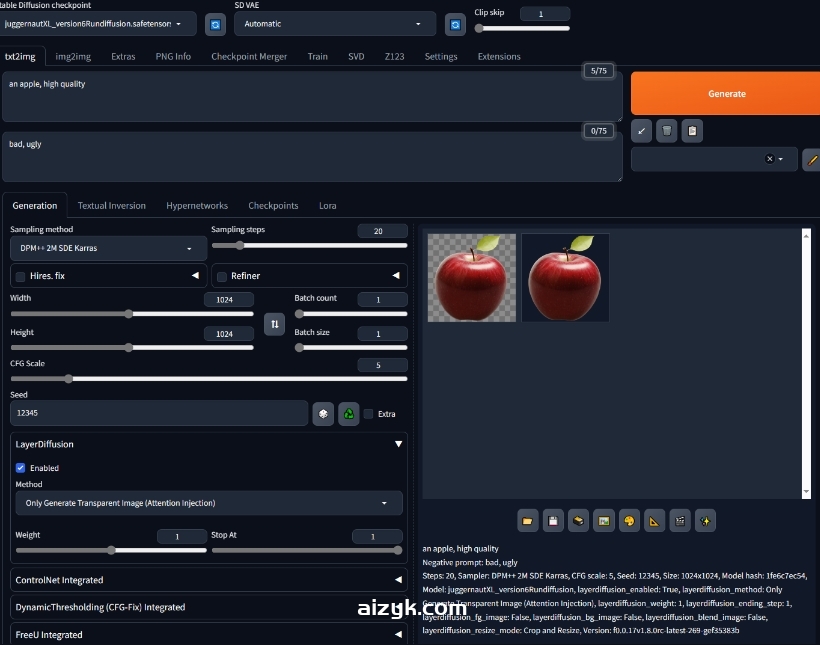
测试的建议模型“Juggernaut XL V6”(如果你想结果一样的话,模型也在资源包下载好了)
你还可以去C站下载“Juggernaut XL V6”(科学上网,注意用的是V6,不是v7或v8或V9,大小:6.62GB)
正面提示:an apple, high quality
负面提示bad, ugly
其他参数:Steps: 20, Sampler: DPM++ 2M SDE Karras, CFG scale: 5, Seed: 12345, Size: 1024×1024, Model hash: 1fe6c7ec54, Model: juggernautXL_version6Rundiffusion, layerdiffusion_enabled: True, layerdiffusion_method: Only Generate Transparent Image (Attention Injection), layerdiffusion_weight: 1, layerdiffusion_ending_step: 1, layerdiffusion_fg_image: False, layerdiffusion_bg_image: False, layerdiffusion_blend_image: False, layerdiffusion_resize_mode: Crop and Resize, Version: f0.0.17v1.8.0rc-latest-269-gef35383b

测试的建议模型Juggernaut XL V6(如果你想结果一样的话,模型也在资源包下载好了)
你还可以去C站下载“Juggernaut XL V6”(科学上网,注意用的是V6,不是v7或v8或V9,大小:6.62GB)
正面提示:
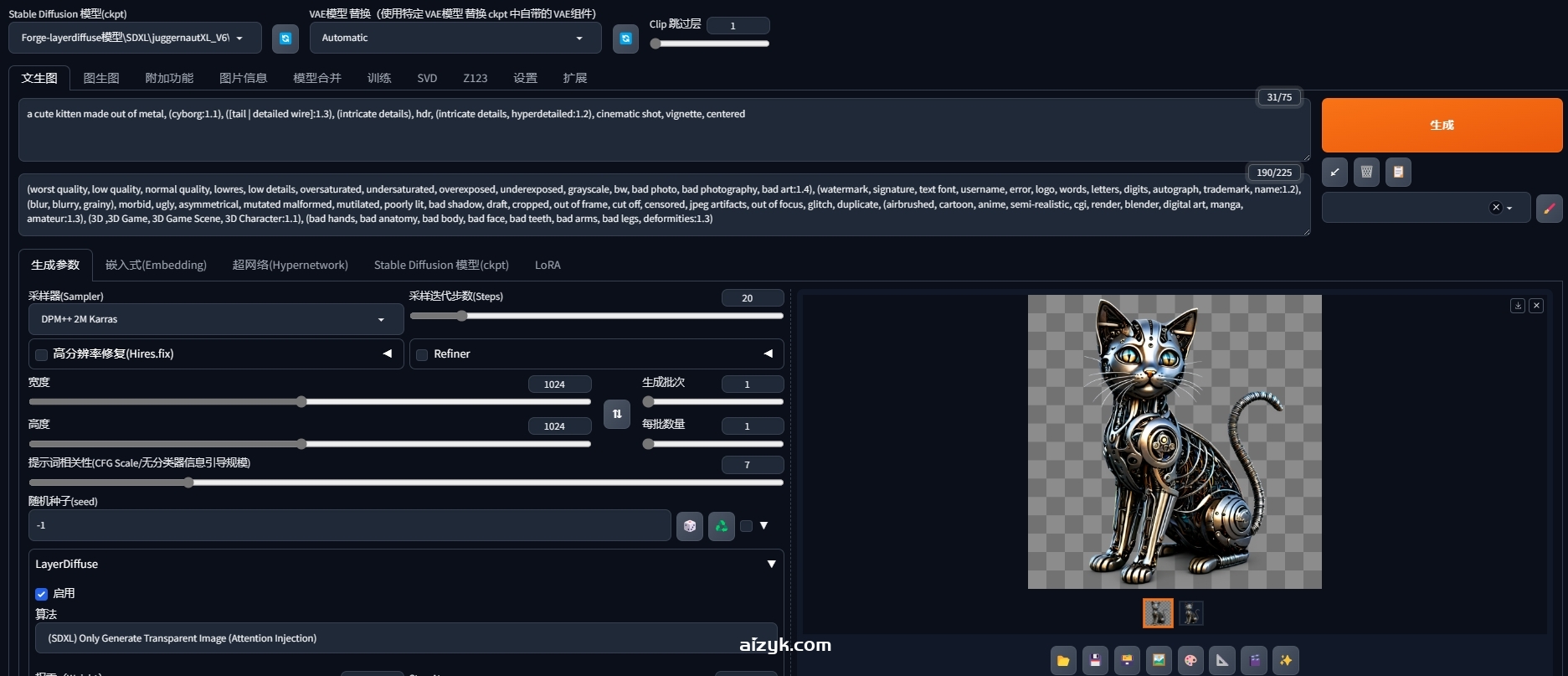
a cute kitten made out of metal, (cyborg:1.1), ([tail | detailed wire]:1.3), (intricate details), hdr, (intricate details, hyperdetailed:1.2), cinematic shot, vignette, centered
负面提示:
(worst quality, low quality, normal quality, lowres, low details, oversaturated, undersaturated, overexposed, underexposed, grayscale, bw, bad photo, bad photography, bad art:1.4), (watermark, signature, text font, username, error, logo, words, letters, digits, autograph, trademark, name:1.2), (blur, blurry, grainy), morbid, ugly, asymmetrical, mutated malformed, mutilated, poorly lit, bad shadow, draft, cropped, out of frame, cut off, censored, jpeg artifacts, out of focus, glitch, duplicate, (airbrushed, cartoon, anime, semi-realistic, cgi, render, blender, digital art, manga, amateur:1.3), (3D ,3D Game, 3D Game Scene, 3D Character:1.1), (bad hands, bad anatomy, bad body, bad face, bad teeth, bad arms, bad legs, deformities:1.3)
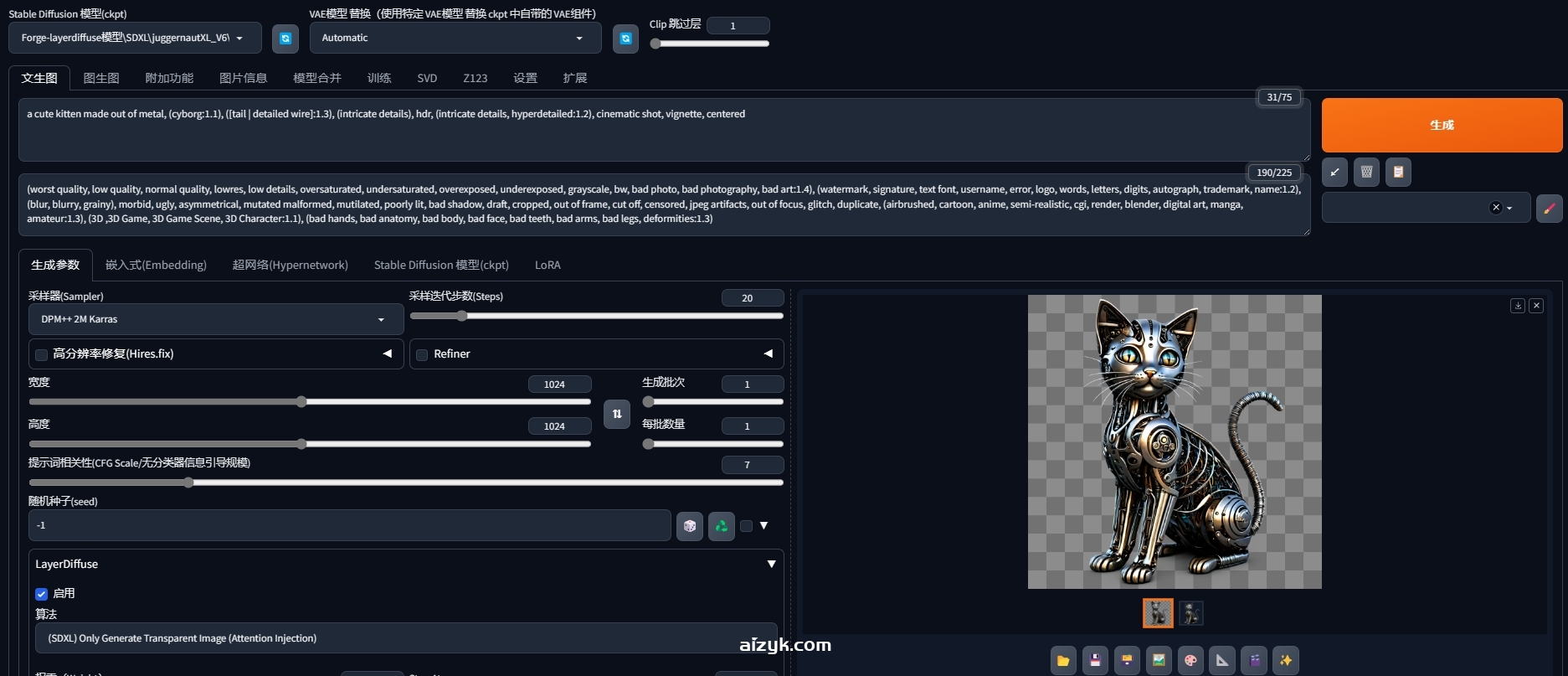

注意:默认只会保存带棋盘格的透明图,无棋盘格的透明图需要手动保存
传送门
[ri-alerts color=”info”]SD-ComfyUI官方原生包软件[/ri-alerts]

(如遇失效,请加v:aizyk2310备注SD)
© 版权声明
文章版权归作者所有,未经允许请勿转载。


