你可能在各种模型和lora以及vae等等版本上见过fp16这个后缀,包括在内核版本上,现在有一个琥珀青叶FP8先行版。
以及最近频繁有人问,某个controlnet带fp16和不带fp16,为什么名字一样,大小不一样?
下面就来解答这个问题。
fp32 fp16 fp8 这其实是三种精度格式,fp是floating-point的缩写,了解一点编程基础的对这个词肯定都不陌生。
说穿了就是三种存储格式,fp32指的是用32位二进制表示的浮点数,fp16就是16位,fp8就是8位。
在此之上还有FP64,甚至FP128,但这些我们日常基本遇不到,一个模型100多G,没必要。
这部分属于编程入门的基础知识,具体的请自行百度,这里不做展开。
简单来说,fp32最完整,可以携带和存储的信息最多,所以在大部分时候,默认使用的是fp32,特别是在训练模型的时候。
而你下载或使用的大模型或者controlnet模型,如果没有特别标注,默认都是fp32的,因此controlnet模型每一个都是1.35G。
但是,实际上在webUI中,默认使用的是FP16,比如启动器上默认的“开启半精度优化”:
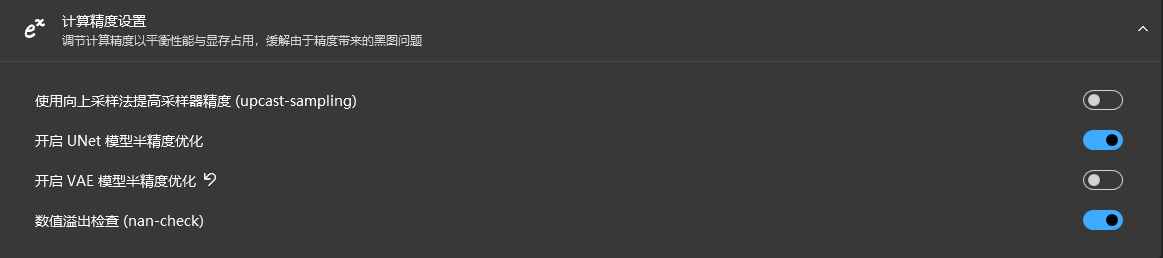
所谓半精度,指的就是FP16,之所以说是优化,就是把原本的FP32转为FP16运行,从而对于占用空间和运算速度都有明显的提升。
因此,有的时候你会看到报错提示需要你开启“float32”或者关闭半精度,其实就是对于FP32和FP16的切换。
切换为FP32会导致运算速度急剧降低,以及多占用显卡内存,更主要的是对于生成效果没有更好的作用,所以一般不建议切换为FP32。
因此,在默认情况下,即便你提供FP32的模型,它在运算之前还是会先转换为FP16的再使用,实际上对于普通用户来说,直接使用FP16模型才是最优选择,因为反正都要转为FP16的,与其载入FP32的模型再让程序转为FP16,还不如一开始就下载FP16的模型,尺寸小了一半,效果不会有任何区别——因为本来程序就要转为FP16。
理所当然的,FP16要比FP32运行速度更快,理论极限是2倍速度差,但因为实际运行比较复杂,肯定不可能这么高,但总之能够提高很大的速度就是了。
而FP8是什么情况呢?跟FP32到FP16的原理一样,8是16的一半,所以存储更小,但运算时需要转回FP16运算,只是FP8转FP16要比FP32转FP16 速度要快得多。但单纯对比速度,自然是FP16不需要转换最快。
那么生成图片的质量有没有差别呢?
这里面涉及到更加高深的数学或者编程知识,不做深度讲解,只说结论:
默认情况下,FP32和FP16的运行结果完全一致,但FP8的运行结果确实与FP16和FP32有细微区别,但这种区别微乎其微,而且不存在好坏的区别,FP8甚至会看起来更加舒适。
总之,对于以跑图为目标的普通用户日常使用来说,无论是大模型还是什么类型的模型,只要有FP16就用FP16,有FP8就用FP8,可以有效提高载入和运行速度。
但是,最后有一点需要特别注意,FP16和FP8的模型,理论上只适合使用GPU运行。
CPU模式运行下似乎只能使用FP32的,这一点我暂时是这样理解。
参考信息链接:
秋叶:https://www.bilibili.com/read/cv26279169/
琥珀青叶:https://www.bilibili.com/video/BV1SQ4y147xh/
强烈推荐大家有兴趣的反复看一看琥珀青叶大佬这个视频 ↑,对于FP各个精度的讲解深入浅出,适合没基础的新人了解,也适合有一定基础的朋友深入理解。
加入Stable Diffusion交流群


(备注:SD)