免费下载
模型+节点:
夸克:https://pan.quark.cn/s/164277dd6fd0
迅雷:https://pan.xunlei.com/s/VNxc9byv3o7MZYRUP46nHzrHA1?pwd=yhb8#
来源github作者:Stability-AI
简介

该模型基于Würstchen架构构建,与稳定扩散等其他模型的主要区别在于它在更小的潜在空间中工作。为什么这很重要?潜在空间越小,推理速度就越快,训练成本也就越低。潜在空间有多小?稳定扩散使用压缩因子 8,从而将 1024×1024 图像编码为 128×128。 Stable Cascade 的压缩系数为 42,这意味着可以将 1024×1024 图像编码为 24×24,同时保持清晰的重建。然后在高度压缩的潜在空间中训练文本条件模型。与稳定扩散 1.5 相比,该架构的先前版本实现了 16 倍的成本降低。
因此,这种模型非常适合注重效率的用途。此外,所有已知的扩展(如微调、LoRA、ControlNet、IP 适配器、LCM 等)也可以通过此方法实现。
Stable Cascade由三个模型组成:Stage A、Stage B和Stage C,代表级联生成图像,因此得名“Stable Cascade”。 A 阶段和 B 阶段用于压缩图像,类似于稳定扩散中 VAE 的工作。然而,通过这种设置,可以实现更高的图像压缩。稳定扩散模型使用 8 的空间压缩因子,将分辨率为 1024 x 1024 的图像编码为 128 x 128,而稳定级联模型的压缩因子为 42。这将 1024 x 1024 图像编码为 24 x 24,同时能够准确解码图像。这带来了更便宜的训练和推理的巨大好处。此外,阶段 C 负责在给定文本提示的情况下生成小的 24 x 24 潜伏。下图直观地展示了这一点。
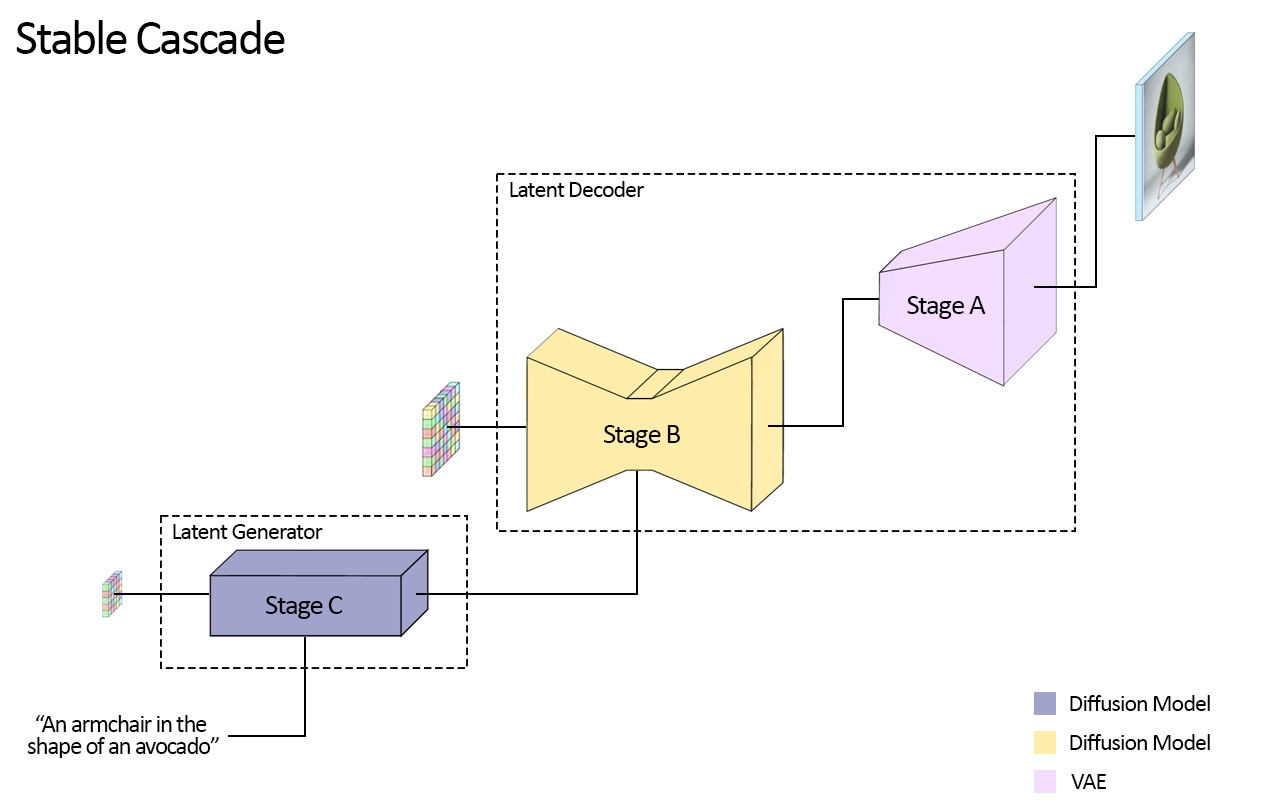
对于此版本,我们为阶段 C 提供两个检查点,两个为阶段 B,一个为阶段 A。阶段 C 提供 10 亿和 36 亿参数版本,但我们强烈建议使用 36 亿版本,因为大多数工作都是投入其微调。 Stage B 的两个版本分别达到 7 亿和 15 亿个参数。两者都取得了很好的成果,但 15 亿人擅长重建微小而精细的细节。因此,如果您使用每个版本的较大变体,您将获得最佳结果。最后,阶段 A 包含 2000 万个参数,并且由于其尺寸较小而被固定。
评估
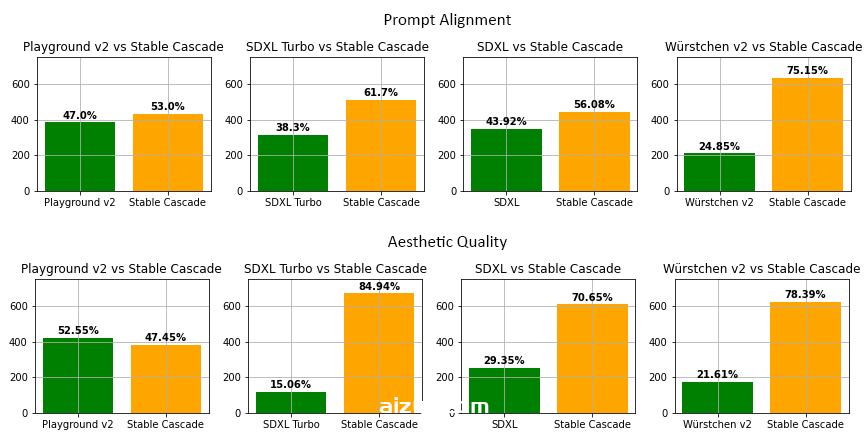
根据我们的评估,在几乎所有比较中,Stable Cascade 在快速对齐和美观质量方面都表现最好。上图显示了使用部分提示(链接)和审美提示相结合的人类评估结果。具体来说,将 Stable Cascade(30 个推理步骤)与 Playground v2(50 个推理步骤)、SDXL(50 个推理步骤)、SDXL Turbo(1 个推理步骤)和 Würstchen v2(30 个推理步骤)进行了比较。
代码示例
⚠️ 重要提示:要使下面的代码正常工作,您必须diffusers在 PR 尚未完成时从该分支进行安装。
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3
import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=torch.float16).to(device)
prompt = "Anthropomorphic cat dressed as a pilot"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
#Now decoder_output is a list with your PIL images
用途
该模型目前用于研究目的。可能的研究领域和任务包括
- 生成模型的研究。
- 安全部署可能生成有害内容的模型。
- 探索和理解生成模型的局限性和偏差。
- 艺术品的生成以及在设计和其他艺术过程中的使用。
- 在教育或创意工具中的应用。
局限性
- 一般情况下,面孔和人物可能无法正确生成。
- 模型的自动编码部分是有损的。
在线体验地址
https://huggingface.co/spaces/multimodalart/stable-cascade
ComfyUI中使用
当然也有大佬做了一个在comfyui中使用的节点,这并不是官方的,不过也够我们尝鲜体验
安装节点
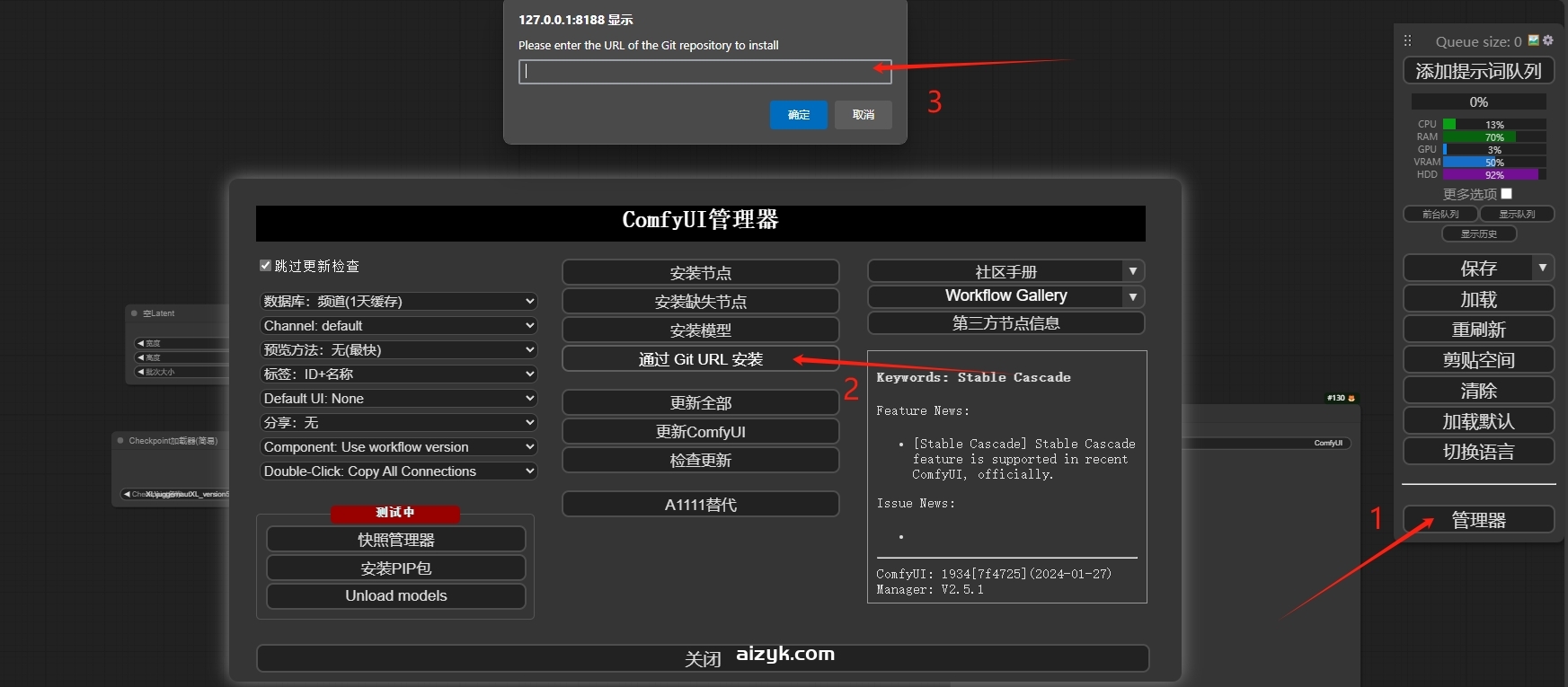
安装方法还是老样子,你可以在右侧下载节点包,解压后放入ComfyUI_windows_portableComfyUIcustom_nodes目录,也可以打开插件管理器“通过GIT RUL安装”来安装该节点,然后重启
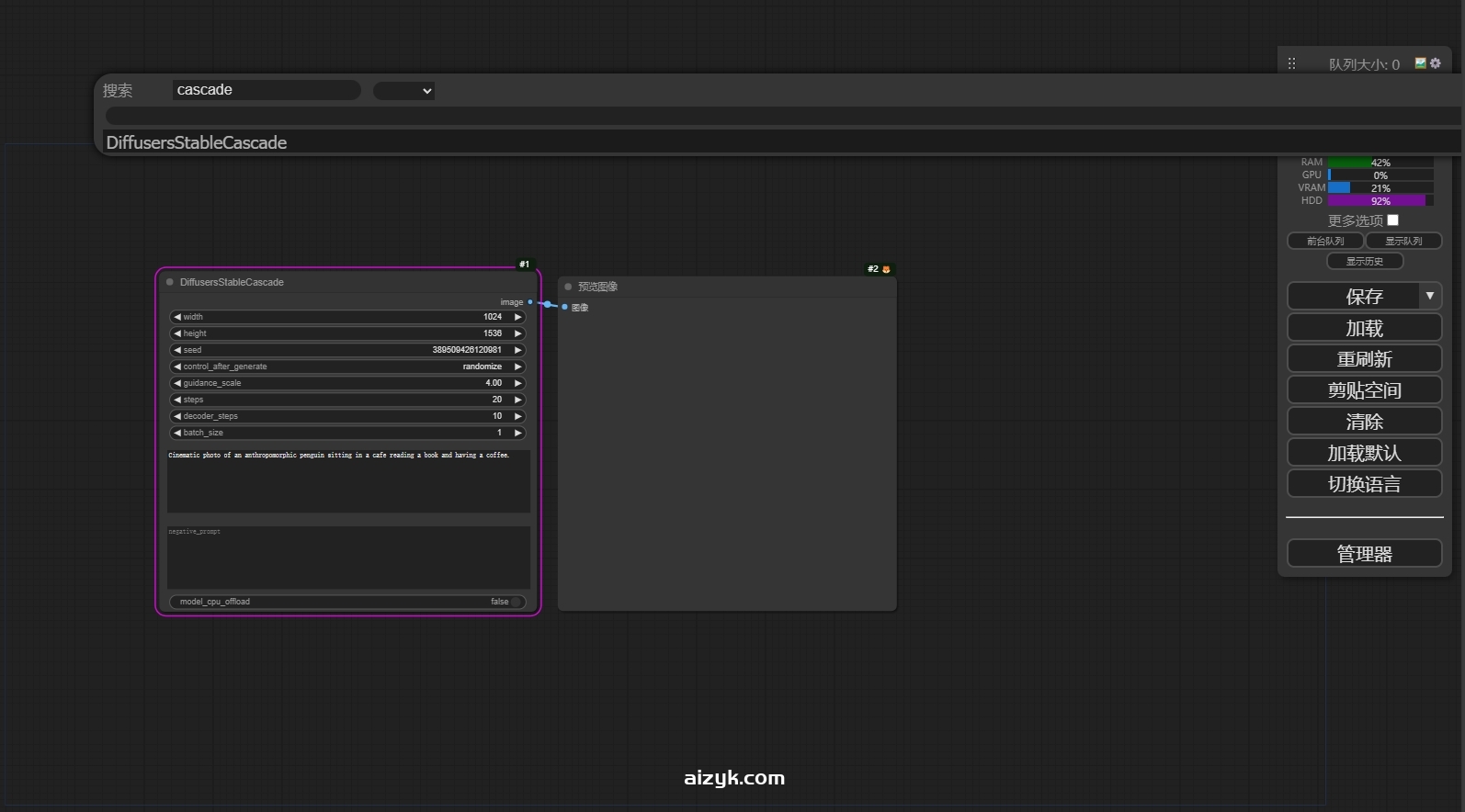
安装成功之后,可以通过搜索关键词“cascade”来添加该节点,此工作流只需一个cascade节点+图像预览保存节点即可运行
注意
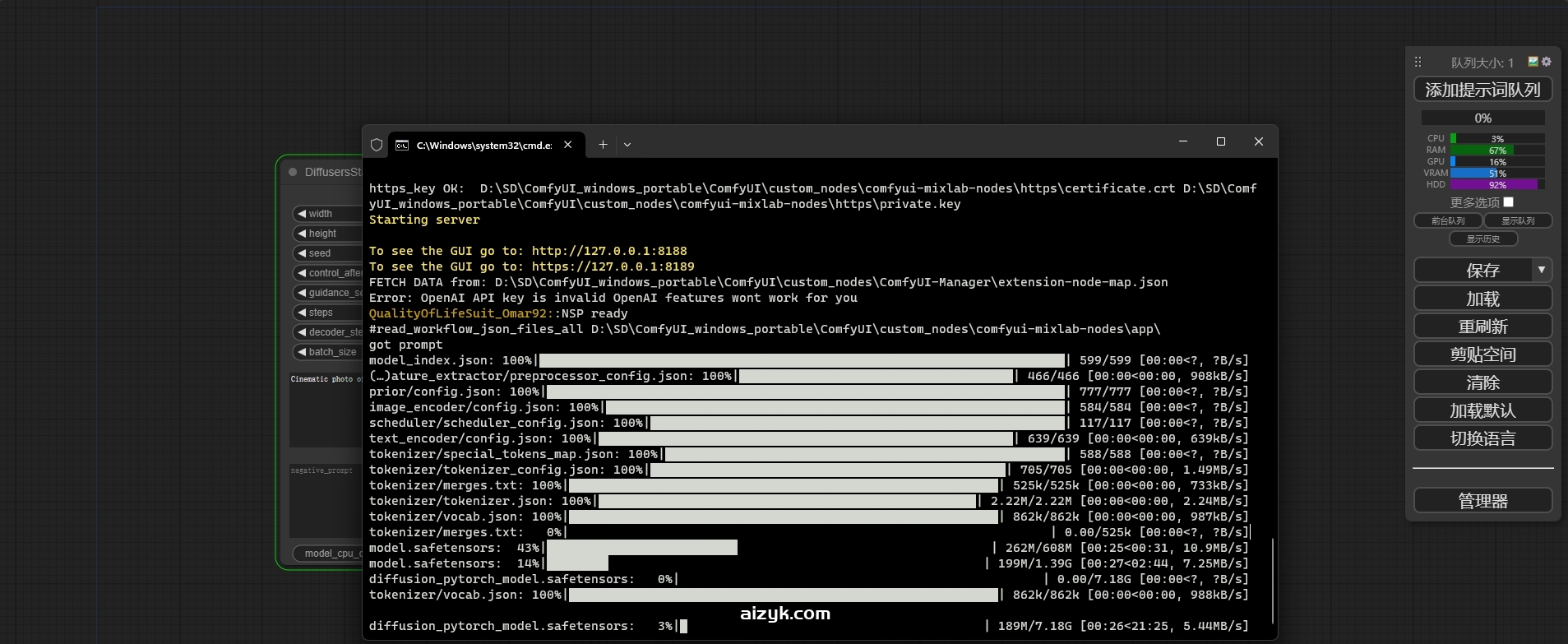
首次运行时,需要从huggingface下载大于21G的各种模型,全程需科学上网
下载后的模型并不是保存在comfyui模型文件中,而是保存在“C:Users你的电脑名称.cachehuggingfacehub”
传送门
[ri-alerts color=”info”]SD-ComfyUI官方原生包软件[/ri-alerts]

(失效请加V:aizyk2310备注SD)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
.jpg)

